/\ __ __
/\ /__\ _____ / /_ ____ _____ /_/__ __ _____
/__\ /\ / ___// __ \ / __ \ / ___// // / / // ___/
\_ /__\ / / / /_/ // /_/ // / / // /_/ /_\ \
\_/ /_/ /_/___/ \____//_/ /_/ \____//____/
/

/\ __ __
/\ /__\ _____ / /_ ____ _____ /_/__ __ _____
/__\ /\ / ___// __ \ / __ \ / ___// // / / // ___/
\_ /__\ / / / /_/ // /_/ // / / // /_/ /_\ \
\_/ /_/ /_/___/ \____//_/ /_/ \____//____/
/
Read the rules
View the card editor
Join us on Reddit
Join us on Discord
Play Arborius!
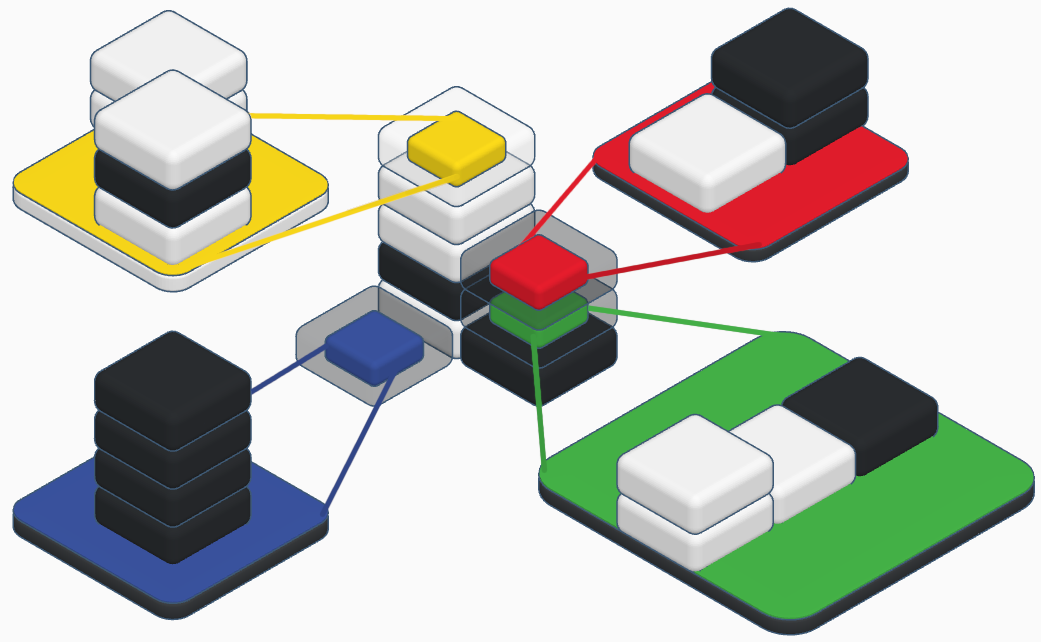
Arborius is a strategic deck builder that seats two players. Players take turns from a deck of stackable tiles, competing the be the last one standing. Tiles have unique abilities, stack vertically in 3d, and can be combined, equipping powerful chains of combo abilities. Players start with one tile in play, and add more as the game progresses.
Every tile has the same Basic Actions:
-Move a stack
-Attack
-Unplay
-Play
-Use abilities
-Enter tiles
-Exit tiles
Solitary tiles with nothing adjacent get destroyed at the end of each turn.
When a tile attacks, the damage it deals is equal to the height of the tallest stack of tiles inside it.
Attacking and defending are calculated as follows:
When a tile takes damage from an attack, the defender must remove that many items from it.
Finally if a tile runs out of items, it is also destroyed.
Click here to read detailed rules with pictures.
All the depth in this game comes from the abilities and the recursive behavior of the item mechanics I’ve designed.
A
4BS
R